Filtre Lidar: le tracker
But du filtre
Le filtre « tracker » est conçu pour filtrer les données brutes du lidar en scannant les données mises bout à bout.
Le filtre traite donc les données distance les unes après les autres sur toute la zone angulaire de détection du Lidar. Son but est de découper les données en blocks de points caractéristiques. On espère que ces blocks soient surtout caractéristiques d’un support balise de Robot de la Coupe de France de Robotique pour lesquels le filtre sera optimisé.
Comme on parcourt les données les unes après les autres (c’est un tableau de distances tout simplement), en représentation linéaire, ça forme des sortes de créneaux (les blocks de points caractéristiques).
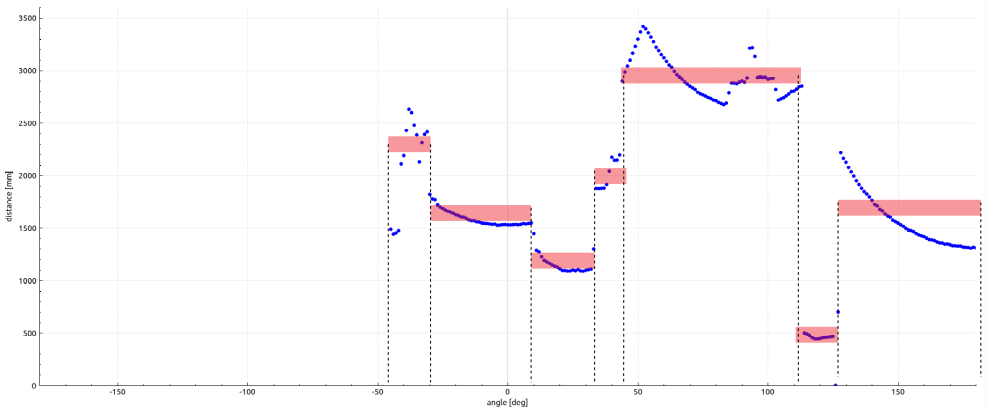
Le filtre va utiliser différents traitements pour former ces créneaux tout en s’affranchissant des différents cas de parasitage des données et en excluant les créneaux aberrants (toujours dans l’objectif de ne détecter qu’un support balise).
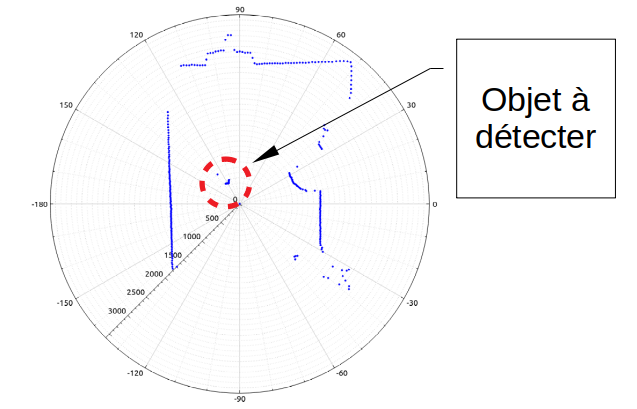
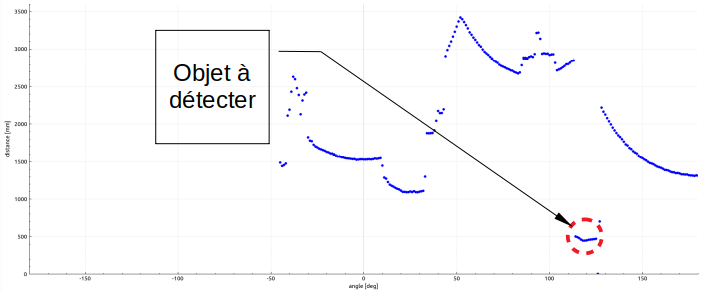
Vue à l’infini
Naturellement, on va fixer un horizon de détection (vision à l’infini: on ne distingue plus ce qui est trop loin). C’est le cas idéal pour l’identification d’un objet: rien n’est détecté autour de l’objet détecté, une sorte de zone « blanche » se forme autour de lui.
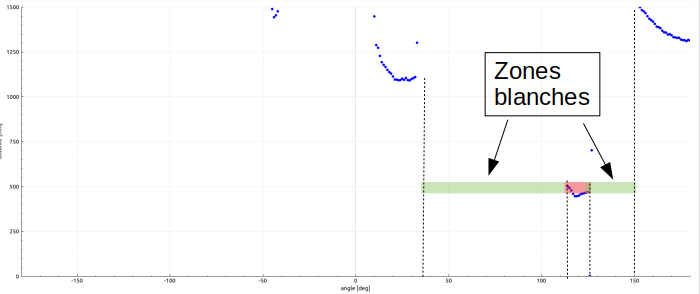
réglages à faire:
- m_d_MAX_dist qui est l’horizon de l’infini, toute mesure au delà ne sera pas prise en compte
- m_i_MAX_BLANK qui une sorte de contraste angulaire, la largeur minimum de la zone « blanche » qui permet de distinguer chaque objet (inversement on s’autorise à perdre quelques points dans notre acquisition, un trou dans le support balise par exemple).
Problème de masquage
Rien ne ressemble plus à une mesure qu’une autre mesure, cependant on peut considérer quand l’écart de mesure est significatif qu’on ne mesure plus le même objet. On peut donc filtrer les forts gradients de distance pour distinguer le fond ou les objets lointains.
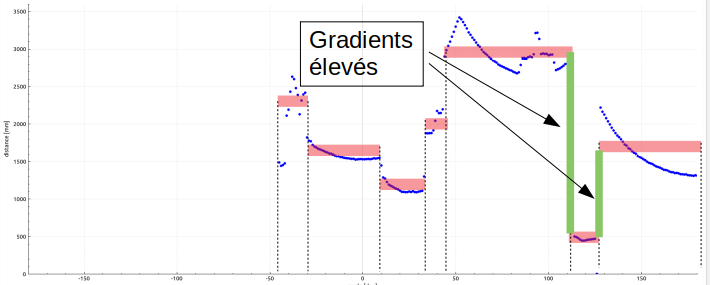
Dans notre cas pour éviter de mesurer les gradients élevés sur des points aberrants (un pixel de bruit par exemple), on calcule l’écart type de distance sur une fenêtre glissante de 5 points. Si l’écart type est élevé, on détecte sûrement un gradient élevé. La méthode peut être améliorée en regardant de façon ordonnée la répartition des points par rapport à la valeur médiane, en effet le contrôle d’un écart type sur un nuage de points très bruité ne sera pas efficace.
Filtrage de la taille de l’objet
Le support balise des robots est normé et ne peut donc excéder une certaine taille donc les nuages de points trop gros ne sont pas des supports balise (peut-être une mascotte de la coupe de France de Robotique passant trop près du Lidar). De même les nuages de points trop petits sont vraisemblablement des mesures parasites à rejeter.
Fusion des objets trop proches
Les supports de balise des robots ont une taille minimum, donc deux objets détectés dans un rayons inférieur à cette taille minimum sont sûrement le même objet.
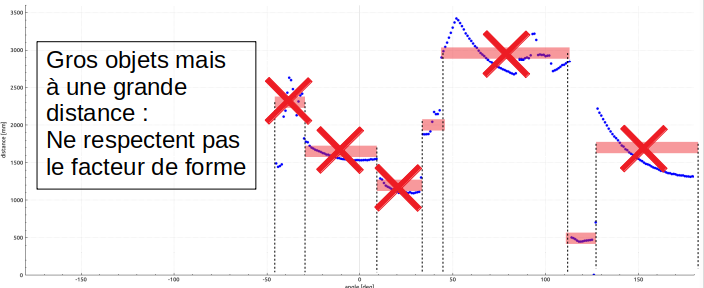
Facteur de forme
Pour filtrer les gros objet apparents donc normalement proches mais pourtant lointains, il y a une relation entre taille de l’objet et sa distance (obtenu par apprentissage pour un objet comme le support balise) c’est le facteur de forme.
L’apprentissage se fait simplement: on approche du lidar une cible caractéristique (un mat balise bien sûr) et on prend le couple de mesures (distance, écart angulaire). Ensuite on interpole les mesures dans son tableur préféré, cette interpolation sera le facteur de forme. Idéalement l’interpolation est linéaire, mais les mesures m’ont fait pencher pour une interpolation polynomiale. Si c’est trop gourmand en calcul on repassera à une fonction affine.
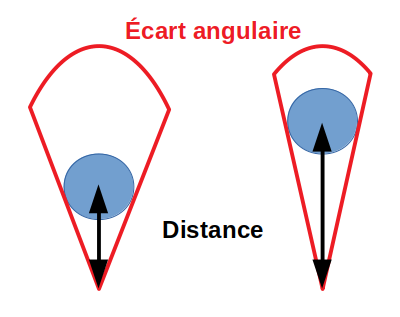
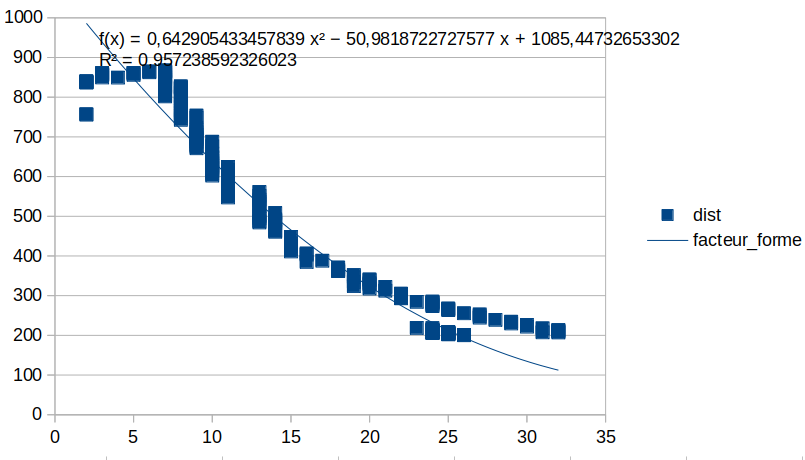
Si le couple taille/distance s’éloigne trop du facteur de forme, il ne correspond pas à une balise.
Le facteur de forme est très sélectif, c’est le premier traitement à « décalibrer » si on détecte plus le support balise (principalement parce qu’il ne respecte pas, ou peu, le cahier des charges: trop mince, à trous,…).